Awhile back we made a post describing how Philter can be used alongside Apache NiFi for identifying and removing sensitive information from text. Since that post, there have been changes to Philter and Apache NiFi so we thought it would be worthwhile to revisit that architecture and its configuration.
- Apache NiFi is an application for creating and managing data flows that process data.
- Philter identifies and removes sensitive information, such as PHI and PII, from natural language text. Philter is available on cloud marketplaces.
The Data Flow Architecture
In the architecture of our data flow, we are going to be ingesting natural language (unstructured) text from somewhere - it doesn’t really matter where. In your use-case it may be from a file system, from an S3 bucket, or from an Apache Kafka topic. Once we have the text in the content of the NiFi flowfile, we will send the text to Philter where the sensitive information will be removed from the text. The filtered text will then be the content of the flowfile. In our example here we are going to read the files from a directory on the file system.
To interact with Philter we can use NiFi’s InvokeHTTP processor since Philter’s API is HTTP REST-based.
Finally, we will write the filtered text to some destination. Like the ingest source, where we write the text does not matter. We could write it back to the source or some other location - whatever is required by your use-case.
The NiFi Flow
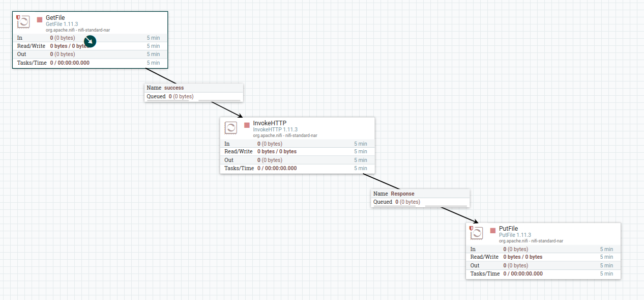
The flow will use the GetFile processor to read /tmp/input/*.txt files. The contents of each file will be sent to Philter. The resulting filtered text will be written back to the file system at /tmp/output.

If you want to quickly prototype it with minimal configuration, use a GenerateFlowFile processor and set the content manually to something like “His SSN was 123-45-6789.”
InvokeHTTP Processor Configuration
The configuration of the InvokeHTTP processor is fairly simple. We just need to configure the HTTP Method, Remote URL, and Content Type. Set each as follows:
Since we are not providing any values for the context, document ID, or filter profile name in the URL, Philter will use defaults values for each. When not provided, the default value for context is default, Philter will generate a document ID per request, and the default filter profile name is default.
These default values are detailed in Philter’s API documentation. A context lets you group similar documents together, perhaps by business unit or purpose. A document ID should uniquely identify a document (such as a file name) and can be used to split up large documents for processing.
If you do want to set values for one or all of those instead of using the default values, just append them to the Remote URL: http://philter-ip:8080/api/filter?c=ctx&p=justssn In this request, the context is set to ctx and it tells Philter to use the filter profile named justssn. As a tip, you can use NiFi’s expression language to parameterize the values in the URL.

A Closer Look
If we use a LogAttribute processor we can get some insight into what’s happening. In the log output below, we can see HTTP POST request that was made.
At the top of the log we see the filtered text from Philter. The input text from the file was “His SSN was 123–45–6789.” Philter applied the default filter profile which looks for SSNs and responded with “His SSN was {{{REDACTED-ssn}}}.”
( Filter profiles are very powerful and flexible configurations that let you have full control over the types of sensitive information that Philter identifies and how Philter manipulates that information when found.)
We can also see that since we did not provide a value for the document ID in the request, Philter assigned a document ID and returned it in the response in the x-document-id header.
His SSN was {{{REDACTED-ssn}}}. -------------------------------------------------- Standard FlowFile Attributes Key: 'entryDate' Value: 'Thu Feb 27 13:35:19 UTC 2020' Key: 'lineageStartDate' Value: 'Thu Feb 27 13:35:11 UTC 2020' Key: 'fileSize' Value: '31' FlowFile Attribute Map Content Key: 'Connection' Value: 'keep-alive' Key: 'Content-Length' Value: '31' Key: 'Content-Type' Value: 'text/plain;charset=UTF-8' Key: 'Date' Value: 'Thu, 27 Feb 2020 13:35:19 GMT' Key: 'Keep-Alive' Value: 'timeout=60' Key: 'filename' Value: 'd206fc81-2c42-40ba-afbf-b5f9998b56c0' Key: 'invokehttp.request.url' Value: 'http://10.1.1.221:8080/api/filter' Key: 'invokehttp.status.code' Value: '200' Key: 'invokehttp.status.message' Value: '' Key: 'invokehttp.tx.id' Value: 'fbf2f6c0-1073-4fac-bc23-6d6a67b70423' Key: 'mime.type' Value: 'text/plain;charset=UTF-8' Key: 'path' Value: './' Key: 'uuid' Value: '486ff4c2-6530-4e1c-aea2-e9965b86b10c' Key: 'x-document-id' Value: 'fb75a2a4c164192542f89881aa8baf21' --------------------------------------------------Summary
Philter’s API makes it easy to integrate Philter with applications like Apache NiFi. The InvokeHTTP processor native to NiFi is an ideal means of communicating with Philter.
To keep things simple, this example only considered SSNs in text. Philter supports many other types of sensitive information.
If performance is very important, there are a couple of things that can be done to help. First, Philter is stateless so you can run multiple instances of Philter behind a load balancer. Second, Philter can run natively inside an Apache NiFi flow without the need to make HTTP calls to Philter. Philter’s integration with applications like Apache NiFi is very important to us so look for more improvements and features in versions to come.